
RESEARCH ARTICLE
A Hybrid Teaching Mode Based on Machine Learning Algorithm
Jinjin Liang1, 2, *, Yong Nie1
Article Information

Identifiers and Pagination:
Year: 2020Volume: 6
First Page: 22
Last Page: 28
Publisher Id: TOAIJ-6-22
DOI: 10.2174/1874061802006010022
Article History:
Received Date: 15/12/2019Revision Received Date: 10/03/2020
Acceptance Date: 03/04/2020
Electronic publication date: 18/06/2020
Collection year: 2020
open-access license: This is an open access article distributed under the terms of the Creative Commons Attribution 4.0 International Public License (CC-BY 4.0), a copy of which is available at: (https://creativecommons.org/licenses/by/4.0/legalcode). This license permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Abstract
Background:
Hybrid teaching mode is a new trend under the Education Informatization environment, which combines the advantages of educators’ supervision offline and learners’ self-regulated learning online. Capturing learners’ learning behavior data becomes easy both from the traditional classroom and online platform.
Methods:
If machine learning algorithms can be applied to mine valuable information underneath those behavior data, it will provide scientific evidence and contribute to wise decision making as well as effective teaching process designing by educators.
Results:
This paper proposed a hybrid teaching mode utilizing machine learning algorithms, which uses clustering analysis to analyze the learner’s characteristics and introduces a support vector machine to predict future learning performance. The hybrid mode matches the predicted results to carry out the offline teaching process.
Conclusion:
Simulation results on about 356 students’ data on one specific course in a certain semester demonstrate that the proposed hybrid teaching mode performs very well by analyzing and predicting the learners’ performance with high accuracies.
1. INTRODUCTION
Education Informatization gives impetus to teaching mode and environment, and brings new ways of learning, such as Massive Open Online Courses (MOOCs), mobile learning, and blended learning. Unal Cakiroglu analyzed the learning performances for distance learners [1] and Robert M illustrated the Principle of Instructional Design [2]. MOOC learning has the merits of low cost and high efficiency and is convenient for personalized and fragmented learning. However, most of the courses are mainly based on video and lack the interaction and communication learning experience with teachers, which is not suitable for deep learning. Liu Chunyun analyzed the learning situation for certain students [3]. According to the “learner-centered” principle, the hybrid learning mode integrates the dominant advantages of supervising and controlling the offline traditional classroom for the educators, as well as the dominant roles of self-regulated and individualized learning through online classroom for the learners. Hybrid teaching is conducive to better exploring and sharing the value of high-quality educational resources and has become a predictable educational ideological reform trend in the international education circle.
Existing research in hybrid teaching includes software development, platform improvement, and teaching practice. Armando Fox [4] introduced MOOC online class to replenish and serve the traditional class on the campus and improve the teaching quality significantly. Wu Di [5] proposed a blended learning mode SPOC (Small Private Online Course), which combines answers to problems from teachers, and completion of independent learning and testing on online courses from students. A SPOC course was proposed by Sun Yujie to carry out the teaching practice, which blends the online and offline teaching combining with the actual development of the school [6]. He Xingyuan analyzed the factors in typical SPOC cases, such as the application basis of learning needs, learning plans, content preparation, measurement, and evaluation [7].
Nevertheless, some problems not be resolved in hybrid teaching are as follows.
(1) What characteristics of learning style are reflected in online learning behaviors?
(2) Can the future performance be predicted using both the online learning behaviors?
(3) How the results can be applied to improve their future academic performance in the offline classroom?
Witten, I. H., and Frank stated that Machine learning is the most important subfield of Artificial Intelligence (AI), which uses a kind of data mining method to make a valuable finding in a large amount of data [8]. In Peña-Ayala’s opinion, Machine learning devotes to design algorithms with the ability to “learn from the past experience”, also it can optimize the analysis iteratively by analyzing the results. The main techniques of machine learning are listed as logistic regressions, decision tree, neural networks, Bayesian networks, clustering and supporting vector machine. Tu Zipei pointed out in his book “The big data revolution” that Application of machine learning in the education field promoted a new area called Education Data Mining (EDM) and became a new hot research area [10], which is not only the embodiment of digital education research but also the inevitable demand. EDM is defined as a new subject committed to developing new methods, using them to better understand students and their learning environment, as well as exploring the unique and growing data from the education environment. The related research raises certain disadvantages as follows.
(1) It lacks a formal description of the prediction of future performance.
(2) It is ignored that different behavior data could reflect different learning styles or learning characteristics.
(3) Data are usually collected from the online courses in one semester for dozens of students but are not used to increase the students’ offline classroom performance.
This paper aims to cope with the above-encountered problems in hybrid teaching, combining the advantages of machine learning to help instructors deeply understand students’ online behaviors, focus on students’ learning style characteristics, and pay more attention to the students in need of help, to reduce the number of students who may fail the course.
To achieve our goals, we firstly use machine learning algorithms to formalize the online learning analysis problem and then constructed a prediction model. The main contributions of this paper are summarized as follows:
Analysis of Students
Analyze the engagement of students using online learning activities and then discuss how these activities correspond to students’ characteristics by using Clustering Analysis to divide them into three categories active, passive, and inactive.
Formalization of Online Learning Prediction
Using the data collected from the online learning platform, we put forward an SVM model to predict a student’s future learning performance.
Proposing a Hybrid Teaching Mode
The proposed hybrid teaching mode uses the predicted results by the machine learning algorithms and matches them to carry out offline prevention and guidance.
The remainder of this paper is organized as follows. Section 2 summarizes the studies related to our work. Section 3 presents the hybrid teaching mode. Section 4 introduces the experimental results and discusses the performance of the machine learning algorithms. Next, the conclusion and future work are drawn. The final part is our acknowledgement.
2. MATERIAL AND METHODS
Education data are formed by various learners, including knowledge foundation, emotional attitude, learning needs, and interaction behaviors, which have distinct characteristics of isomerism, highly nonlinear correlation, and multi-mode. Analyzing the education data based on an educator’s goals will provide efficient powerful evidence and contribute to optimizing and designing individualization and differentiation teaching strategies and activities. If educators can understand the learners, they can recommend suitable resources and teaching strategies to match learners’ actual situation, thus carry out the teaching process according to students’ natural ability. It can also help to select the teaching contents by understanding the grasping situations and practical needs. The target variables are designed differently under the two different situations: the learners and the resources. The former is characterized by learners’ emotions, attitudes, scores, etc; the latter is formed by the subjective sensation, testing results, learning frequency of the resources. Clustering analysis is introduced to classify the learners into various groups based on similarity among the education data. We analyze the important and difficult teaching content, put emphasis on needed explanation and testing, and recommend high-quality resources.
Learning situation analysis is the educator's diagnosis, assessment, and analysis of various factors affecting learners' learning, which provides the basis for designing teaching strategies and optimizing teaching content. By setting different methods and models for learning data, learning situation analysis can explain learners’ learning performance, explore the problems existing in the learning process, and provide corresponding feedback. The results of learning situation analysis change dynamically with learners' learning behavior and situation, they can provide a scientific basis for educators to carry out personalized tutoring and resource recommendation throughout the whole teaching process, thus realizing personalized and accurate teaching. Fernandes E [11]. used psychological theory to analyze the learning situation and point out that learners' psychology should be paid attention to in educational activities. Li Qiang [12] established the theory of learning classification compatible with various viewpoints and pointed out that classification analysis must be carried out before the design of the teaching system. Shu-Fen Tseng and his partners carried out the systematic differential teaching [13], based on the results of the analysis of the learning situation, and the data feedback was applied to improve the teaching. Asher S. B. pointed out that matching learner characteristics design teaching can make teaching more targeted and effective [14]. Gawande R. explored students' problem-solving strategies and existing difficulties through learning situation analysis [15]. Zhang Changjiao summarized the methods of learning situation analysis such as observation, interview, and questionnaire and literature research [16]. Dalipi F. imitated the way of outpatient communication to master the learning situation and design teaching methods [17]. Lu Liusheng analyzed the students’ learning status, he suggested that the analysis of the academic situation should integrate qualitative and quantitative methods [18]. Chen H. J. classified the method of learning situation analysis into two categories [19]: Empirical judgment and empirical analysis. The former is based on the teaching experience of “daily use and routine practice”, while the latter is based on the objectivity of “evidence” collected through written data analysis, interviews, and tests. These studies either focus on the connotation, function, and practicability of learning situation analysis, and most of the methods adopted are based on subjective experience.
The development of machine learning provides a comprehensive and accurate analysis of the academic situation, ideas, and technical support. For the learners of the MOOC platform, Yuan Zhang proposed a score prediction model based on Neural Networks [20]. Setting up appropriate machine learning algorithms will help optimize the teaching process and improve the teaching quality. Wang Jianguo summarized the application of large and medium data technology in academic situation analysis from the perspective of framework theory [21], which gives needed guidance for following researchers. Liang Jinjin stated that Support Vector Machine (SVM) had a solid theoretical basis of statistical learning theory and optimization theory [22], which adopts the principle of structural risk minimization to compromise the contradiction between maximizing the classification interval and minimizing the classification error. The training equals a constrained convex quadratic programming and induces a global optimal solution, and then construct a classification decision function to predict the index of samples. SVM is sparse where a small number of support vector samples determine the final classification function; SVM has the advantages of high classification accuracy, few selection parameters, strong generalization ability, and has good performance in non-linear, high-dimensional pattern recognition problems, and many practical problems. Learning data includes many factors, such as emotional attitude, learning style, etc, that arise from different levels of the teaching process, and the data is highly non-linear. Using SVM to mine learning data, learners’ learning status can be accurately grasped, learners' learning risks can be classified, and early warning and intervention can be made according to the risk level.
3. THE HYBRID TEACHING MODE
The process of the proposed hybrid teaching mode is illustrated in Fig. (1).
The hybrid teaching mode integrates the results with the whole teaching process, recommends learning resources, designs activities, gives an early warning, and carries out intervention for students with learning risk; it firstly collects the data from the online learning environment, and then uses machine learning algorithms to construct the models and finally applies the results to carry out the teaching validation. The proposed mode is expected to promote the teaching and learning effects, by analyzing the online learning data and combining the results with classroom learning through practice.
It should be noted that the algorithms are the core of the teaching mode, the clustering analysis is used to analyze the individual differences in learners’ knowledge base and learning style, and SVM algorithm is introduced to predict the learners' learning risk. The hybrid teaching mode mainly consists of three phases: the data preparation phase, model construction phase, and the evaluation phase, whose detailed explanation will be explained below.
3.1. Data Preparation Phase
Data preparation is the first phase, which prepares the data by collecting the inner features, cleaning them, and transforming them into appropriate forms from the online platform. The data are directly collected from the online platform and have attributes like student name, course completion ratio, number of posts in the forum, homework completion ratio, course interaction time, number of interactive days in the course, etc. Pre-processing includes data cleaning and detects erroneous or irrelevant data and discards them. Such as delete the missing scores and inconsistent data, as well as those insignificant for the study. Also, the data are transformed into approximate forms by data transforming including smoothing or feature construction, which works to remove the noise from the data. Smoothing can also serve as the data reduction, since it may reduce the number of distance attributes by binning, regression, and clustering techniques. Attribute construction designed new attributes and added from the given set of attributes to help the mining process.
3.2. Model Construction Phase
3.2.1. Learner’s Analysis by FCM
Clustering uses the principle of “Intra-group Distance Minimization” and “Inter-group Distance Maximization”,it classifies the samples into various groups,where samples in the same class have high similarity and samples in the different class have high differences. The commonly used clustering algorithm is divided into division method, hierarchy method, density method, grid method, probability model, etc.
 |
Fig. (1). Design of the hybrid teaching mode. |
For the collected behavior data, clustering analysis can be used to analyze the learners with respect to the knowledge foundation, learning habits, general characteristics, and emotional attitude. Take Solomon’s learning style, for example, the Learners are classified into four classes and eight types from four aspects of information processing, perception, input, and understanding: active and contemplative, perceptive and intuitive, visual and verbal, sequential and comprehensive. Learners are described as different classes, and then the educated can design corresponding activities, such as recommending resources, designing content, optimizing the teaching process, etc.
Without loss of generality, we illustrated the C Means clustering which has the merit of simplicity and only requires the initial center. Denoted by 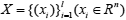 , the Learner’s behavior data, where xi is the i-th training data in the Rn containing n attributes. Clustering analysis is used to divide all the data into c disconnected subsets Xi(i = 1,L ,c), satisfying
, the Learner’s behavior data, where xi is the i-th training data in the Rn containing n attributes. Clustering analysis is used to divide all the data into c disconnected subsets Xi(i = 1,L ,c), satisfying
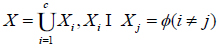 |
(1) |
C Means clustering trains the following objective function with minimal square distances
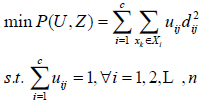 |
(2) |
Here U = (uij)cx1, is the membership matrix, where uij = 1 means the j-th data are assigned to the i-th cluster Z = {z1, z2,...,zc} and uij = 0 means the j-th data are not assigned to the i-th cluster; is the centers for each cluster; dij is the Euclidean distance from the j-th sample to the i-th cluster center, which is computed by
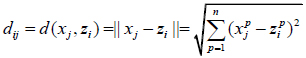 |
(3) |
where 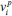 is the-th attribute of any column vector
is the-th attribute of any column vector 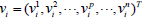 .
.
Select c samples as the initial cluster center; C Means clustering assigns the samples to the nearest clusters; compute the new cluster center and repeat the whole process. Until the objective function is minimized.
3.2.2. Performance Prediction by SVM
Support Vector Machine is used to predict the students’ future performance using the given behavior data, whose traditional applications are two classification problems. SVM uses the principle of “Structural Risk Minimization”, classifies the Learners into different levels.
Denoted by 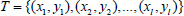 , the learners’ behavior data as the training set, where Xi ϵ Rn is the column vector collected from the teaching process for the i-th learner; yi=1 indicates students with good performance and yi=-1 indicates students with bad performance.
, the learners’ behavior data as the training set, where Xi ϵ Rn is the column vector collected from the teaching process for the i-th learner; yi=1 indicates students with good performance and yi=-1 indicates students with bad performance.
SVM aims to find the optimal separating hyperplane and separates data into two disconnected classes. Introducing a set of slacks 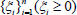 for each misclassified data to allow errors, and pay a penalty C > 0 proportional to the amount of constraint violations; SVM minimizes the following program with “Structural Risk Minimization” principle to get a decision function with good generalization and high precision. The linear separable cases can be formed in the same framework, and we will illustrate the nonlinear separable case without generality.
for each misclassified data to allow errors, and pay a penalty C > 0 proportional to the amount of constraint violations; SVM minimizes the following program with “Structural Risk Minimization” principle to get a decision function with good generalization and high precision. The linear separable cases can be formed in the same framework, and we will illustrate the nonlinear separable case without generality.
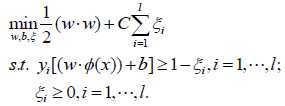 |
(4) |
The optimal separating hyperplane to be defined is (w.x) + b = 0, where w ϵ Rn is the normal to the separating hyperplane, b ϵ R is the bias, (x.y) is the inner product of x and y ; 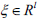 is the constraint violations or called the error. The linear separating hyperplane is exactly one straight line in the two-dimensional space R2 ; and it is one flat surface in the three-dimensional space R3.
is the constraint violations or called the error. The linear separating hyperplane is exactly one straight line in the two-dimensional space R2 ; and it is one flat surface in the three-dimensional space R3.
The dual technique in optimization theory is utilized to transform the above program into one dual program and figure out the solution. Please refer to reference [16] for detail. Denote the Lagrange multiplier as 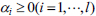 , the dual program is minimized as follows in SVM.
, the dual program is minimized as follows in SVM.
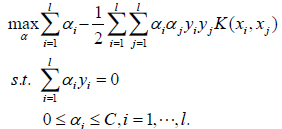 |
(5) |
Here 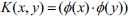 is the kernel function. The commonly used kernels are the linear kernel function
is the kernel function. The commonly used kernels are the linear kernel function , polynomial kernel function
, polynomial kernel function 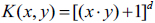 and Radial basis kernel function
and Radial basis kernel function 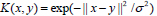 .
.
For the new input data, we use the sign function to predict the label for any new data
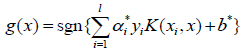 |
(6) |
3.3. Evaluation and Application
Teaching mode refers to a relatively stable framework and procedure of teaching activities under the guidance of certain teaching ideas or theories, which is not omnipotent and fixed for any kind. The hybrid mode includes the mixing of various learning resources, learning objectives and learning bases, and teaching activities, which enriches the concept of education and provides a common teaching paradigm for universities. In the evaluation and application phase, we evaluate the machine learning algorithms of the constructed models and apply their results to carry out the hybrid teaching process. Face-to-face classroom teaching is conducive to in-depth learning, while online learning supports learners ‘self-management. Hybrid teaching mode combines the advantages of both modes, it takes the learners as the centers and allows them to learn independently online, but provides the educators useful information to organize the in-depth offline learning by giving personalized counseling and intervention, so as to promote learners’ deep and comprehensive individualized learning from multiple perspectives.
The proposed hybrid teaching mode uses the constructivism learning as the theoretical guarantee, educators actively organize and design teaching activities, fully communicate with students, and complete teaching tasks in the collision of thinking. The results of machine learning algorithms are utilized as effective teaching resources to help educators optimizing the teaching content, design teaching activities, and adjust teaching strategies. Using the online learning behavior data, clustering analysis is carried out to classify learners' learning styles while SVM is used to predict future performance, according to the knowledge foundation, cognitive reflection, and enthusiasm for participation. Matching the predicted results, the educators give assignments, recommend learning resources, such as audio, video, pictures and texts, and dynamically optimize the teaching process in the offline classroom. The hybrid teaching mode creates an individualized student-based teaching educational frame, by applying machine learning algorithms and providing personalized resources as well as carrying out the personalized guidance for educators.
4. EXPERIMENT RESULTS
This section demonstrates the performance of the proposed hybrid teaching mode. We firstly adopt clustering analysis to analyze the learning characteristics with the online data, then introduce SVM to predict the learning performance, and finally design the teaching process to demonstrate the practical effects. Particularly, Matlab 7.01 is used for simulating the corresponding algorithms. Data used in this research are collected from a course on the Fanya platform named “The Artistic Tactics of the CCP on Struggle during Yan’an Period” which is carried out for the sophomore and junior university students and opened from 2012 until now. In the fall semester in 2019, about 256 students learned the course and they are asked to complete the online learning activities and participate in offline classroom learning for a total of eight weeks. The former online activities are recorded by the platform consisting of many items, such as signing the name, watching videos, participating in quizzes and exams. In addition, discussion forums are required for students to take part in. The latter offline activities include attending the class, submitting assignments, and taking the final test. Each student completes the online learning by the app with a mobile phone or by the website with personal computers. Activities in the app or website are recorded synchronously.
We firstly use the fuzzy C Means to analyze the learners’ styles. After the data preparation step, a total of 238 students were collected into three categories. Set the parameters, the learners are classified into active, passive, and negative ones. Active users are active in learning activities, actively speak in the forum, actively finish their homework, and learn more than 60% of the course content. Passive learners, who use traditional learning methods, only watch videos, browse courseware, and finish homework. Negative learners have passive learning, few learning activities or less learning behavior, and lack of autonomous learning ability. The detailed analysis results are illustrated in Fig. (2), according to it there are only 10 active users, 80 passive users, and the rest 148 are negative users.
 |
Fig. (2). Analysis learners. |
To evaluate the performance of SVM, we construct the confusion matrix in (Table 1).
| - | Predicted Class | ||
|---|---|---|---|
| Fail | Pass | ||
| Actual Class | Fail | TP | TN |
| Pass | FP | FN | |
Three metrics are directly defined from.
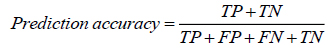 |
(7) |
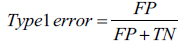 |
(8) |
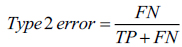 |
(9) |
To show how early we can accurately predict the performance, we respectively generate the datasets from the first two weeks, the first five weeks, and all the eight weeks. We randomly extract half of them as the training set, and the left as the testing set. The experimental evaluations are reported using the averages results of ten trials. The penalty parameter is set C = 1, the radial basis kernel function is used with kernel width δ = 0.1. Table 2 illustrates the results of SVM.
| Data | Prediction Accuracy | Type 1 Error | Type 2 Error |
|---|---|---|---|
| First two week | 0.893 | 0.005 | 0.132 |
| First five week | 0.950 | 0.003 | 0.089 |
| Full eight week | 0.952 | 0.004 | 0.091 |
Based on the above table, we can see SVM, respectively, has prediction accuracies of 0.893, 0.950, and 0.952 using data on the first two weeks, first five weeks, and full eight weeks. Also, we can see that the Type 1 error is much lower than the type 2 error; and we can conclude that SVM can correctly predict the performance using data for the first five weeks.
Using the analysis results with online data, we recommend appropriate resources for students with various learning styles and optimize the teaching strategy; give early warning, personal guidance, and intervention. Practical results demonstrate that the hybrid teaching mode performs quite well, since all the students pass the course.
5. DISCUSSION
This paper is a good example of a hybrid teaching mode, and has very good results in real application scenes. For the unsolved problems in hybrid teaching such as analyzing the learning style, predicting future performance, and utilizing the results to improve future performance in the offline classroom, this paper formalizes the framework of hybrid teaching mode using the data collected from one school semester in one college. But for the students’ privacy reasons and the academic reason, the data could not be disclosed. The next research will focus on research on available public data.
CONCLUSION
Basically, learners’ activities can be recorded in learning management systems under e-learning environments. Different learning styles usually can be reflected in learners’ behavior activities and will lead to different learning performances. Using the online learning data, this paper constructs a hybrid teaching mode by introducing clustering analysis and support vector machine. The results of algorithms give scientific evidence to educators, which help promote learning and teaching. Simulation results on the real application scene demonstrate that the hybrid teaching mode can accurately predict learners’ future performance as early as the fifth week. By recommending the teaching resources, designing teaching activities, and carrying out teaching intervention, all the students pass the course. The next research will generalize these algorithms into the offline classroom, design the prediction indicators, and predict future learning performance.
CONSENT FOR PUBLICATION
Not applicable.
AVAILABILITY OF DATA AND MATERIALS
The raw/processed data required to reproduce these findings cannot be shared at this time for two reasons, one is due to the consideration of students' data privacy, and the other is due to an ongoing study where those data also form part of the research.
FUNDING
The research for this paper is supported the project "Resource construction and application of teacher information ability training platform (2015ET001)",funded by Shaanxi Xinzhi Education Information Research Institute.
CONFLICT OF INTEREST
The authors declare no conflict of interest financial or otherwise.
ACKNOWLEDGEMENTS
Sincere gratitude is given to my postdoctoral mentor, for his generous encouragement and valuable comments on the writing of this paper. Sincere thanks are given to the dealing manager and editors for kindly giving the instructive suggestions, which makes the paper more flawless. Thanks are also given to the anonymous reviewers and experts for providing valuable advice and access to the related resources on this paper. Without their diligent work, the present paper would not have been accomplished.
